

Vida de perros en Madrid
Buscando el mejor distrito para vivir si eres un perro

Ahora que ando buscando —y encontrando :D— piso en Madrid, una de las cosas que pesa en la decisión es cómo de cerca tengo los sitios para pasear a mi perro Churro.

Qué datos buscar y dónde están
Para este análisis he tirado de la página de datos abiertos del Ayuntamiento de Madrid, y estos son los datos que he descargado:
Accidentes por distrito
Animales domésticos por distrito (perros y gatos)
Animales peligrosos por distrito
Árboles por distrito
Número de áreas caninas por distrito
Papeleras con dispensadores de bolsas de caca por distrito
Zonas verdes por distrito (superficie y número de zonas verdes)
Descargando estos datos en CSV y jugando con pandas, me he montado un dataset agregado por distrito con esta pinta:
He de decir que no todos los datasets están igual de actualizados. Para todo he cogido los datos de 2020 mientras que para “Animales domésticos por distrito” lo más actualizado era 2019. No os enfadéis por esta falta de rigor, que estamos en Semana Santa…
Análisis inicial
Antes de ver qué distrito es mejor para ser perro en Madrid, voy a cotillear un poco.
Accidentes por distrito
Gana Salamanca (boooo). Ganar aquí no mola.
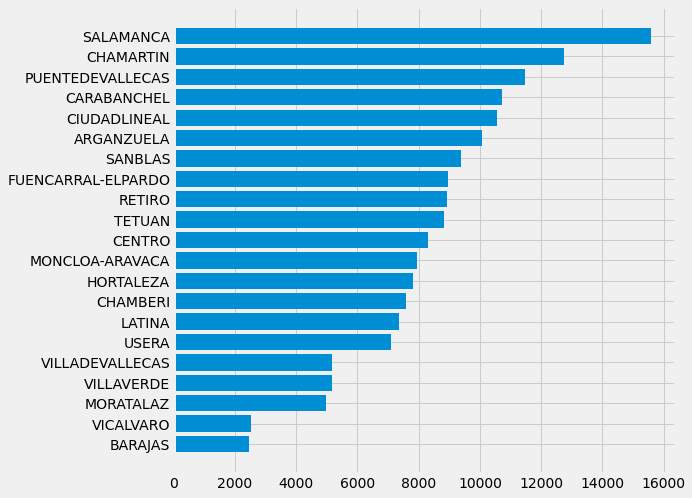
Árboles por distrito
Gana Fuencarral - El Pardo (olé!). Ganar aquí sí mola.

Zonas verdes por distrito
Fuencarral - El Pardo again.

Al lío
Viendo todas las variables que hemos conseguido del centro de datos abiertos, vamos a construir un índice canino de calidad (ICC) con valores entre 0 (peor distrito) y 1 (mejor distrito).
Empiezo creando relaciones entre cada variable y el número de perros de cada distrito.
Por ejemplo, el ratio árboles_por_perro lo calculo como arboles / perros en cada distrito. Este ratio nos interesa que sea lo mayor posible, para que haya muchos árboles disponibles para que cada perro haga pis a gusto. En cambio, el ratio accidentes_por_perro nos interesa que sea lo más bajo posible puesto que queremos un barrio con pocos accidentes relativos.
El ICC es la fórmula que relaciona estos ratios, agregándolos en un único valor. Para mantener esta idea de favorable/desfavorable en la fórmula, los ratios favorables se quedan en el numerador y los desfavorables van al denominador.

Además, y para evitar tener un ICC con unidades del tipo
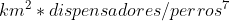
he normalizado cada uno de los ratios dividiendo cada uno por su valor máximo, y así conseguir magnitudes adimensionales entre 0 y 1.
Mejor barrio según ICC
Gana Barajas!

Pero vamos a ver en detalle cada distrito en función de los ratios individuales que conforman el ICC:

Vemos que Barajas es bastante bueno en general y en dispensadores por perro en particular. Con todo esto, alcanza el máximo valor en ICC de todos los distritos de Madrid.
Cosas curiosas:
Más accidentes en zonas tradicionalmente de pasta: ¿más pasta = más coches? Digo yo.
Más gatos por perro en Centro, Latina y Hortaleza.
Más perros peligrosos en Vicálvaro, Moratalaz y Puente de Vallecas.
Sigamos.
¿Que por qué marco Chamartín en naranja? ¡Porque el 1 de Mayo me mudo a Chamartín! Para más información sobre esto, visitad mi newsletter sobre datos de salud para encontrar más información y entenderéis más sobre el porqué de este cambio.
Parece que Chamartín como distrito no es tan bueno, de hecho es el 4º peor en ICC, pero la zona a la que voy no os preocupéis que tiene de todo para Churri Gagarin.
Una vuelta de tuerca al análisis
Ahora que sabemos qué barrio es mejor, podemos coger el dataset agregado, y entrenar un árbol de decisión a predecir el ICC de una zona cualquiera.
Lo bueno de los árboles de decisión es que son fáciles de entender:
Para cada variable de entrada (feature) y cada valor de esa variable, vamos creando particiones
En cada partición, medimos la pureza mediante el coeficiente de Gini
Para la variable y valor que creen las particiones más puras creamos un nodo que parta en dos ramas, y volvemos a empezar (recursión!) hasta tener tantos nodos y tan puros como queramos
Para entrenar el árbol voy a utilizar sklearn en Python y en pocas líneas de código lo conseguimos.

Y aquí el árbol ya entrenado

Vemos que sup_zonas_verdes_km2 aparece en 3 particiones, esto nos da una idea que de que esta variable es importante a la hora de predecir el ICC. Podemos ver cuánta importancia aporta cada variable mediante la propiedad feature_importances_ de nuestro árbol ya entrenado:

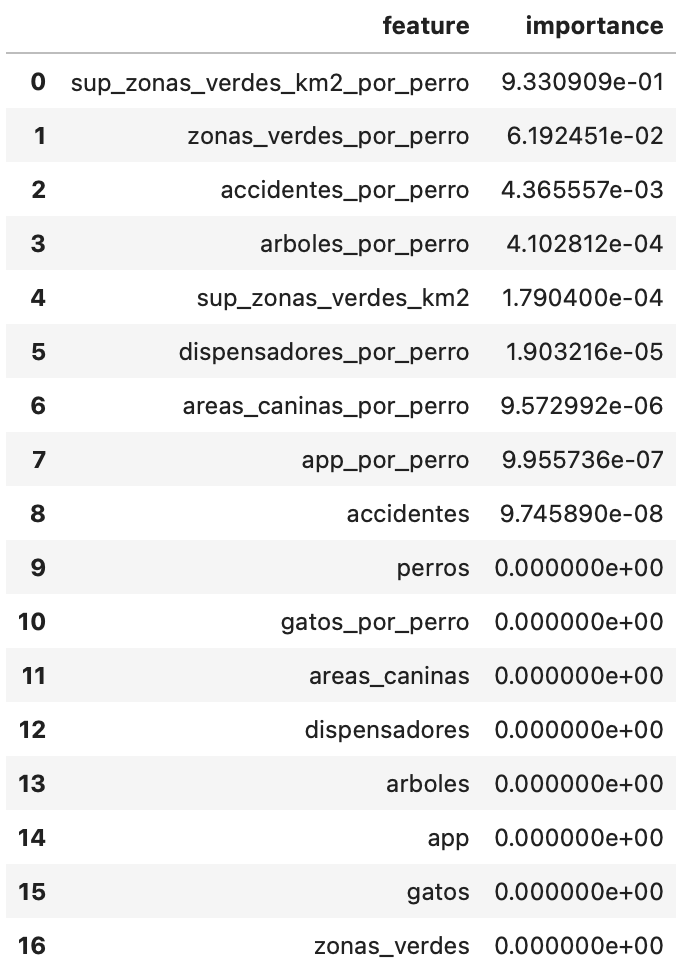
sup_zonas_verdes_km2 contiene el 93% de la importancia de cara a predecir el ICC, así que si queréis calcular un un ICC aproximado, con sólo buscar el distrito que maximice el ratio de superficie de zonas verdes por perro tendremos una buena idea.
Lecciones
Los buenos repositorios de datos abiertos ayudan al ciudadano de muchas maneras, como a la hora de hacer newsletters y así poder seguir dando la brasa. Cuanto más dato abierto mejor.
Si queréis mudaros a Madrid y sois perros, id a Barajas y evitad Chamberí.
Mediante un simple árbol de decision podemos predecir el ICC de una zona cualquiera, y sabemos que sup_zonas_verdes_km2 es un gran proxy de calidad canina!